
API Resiliency Testing is essential for maintaining the reliability and user satisfaction of complex distributed applications. This blog will explore practical tools and techniques to enhance API resilience, ensuring that APIs can gracefully handle unexpected situations.
Table of Contents
- Introduction to API Resiliency
- Chaos Engineering and Fault Injection
- Performance Testing Considerations
- Building Observability into APIs
- Live Demo: Testing an Order Service
- Simulating Timeout Responses
- Updating API Specifications for Resiliency
- Testing for 400 Series Errors
- Using Middleware for Input Validation
- Summary of Key Insights
- FAQs on API Resiliency Testing
Introduction to API Resiliency
API resiliency is the ability of an API to handle failures gracefully. In today’s interconnected applications, a single API failure can lead to cascading issues across multiple services. This phenomenon not only affects user experience but can lead to significant operational challenges.
To achieve effective API resiliency, developers must adopt proactive strategies that encompass robust design, thorough testing, and continuous monitoring. The goal is to ensure that APIs can withstand unexpected failures and continue to provide essential services.
Understanding the Snowball Effect
The Snowball Effect describes how a single failure can trigger a series of failures in dependent systems. When APIs go down, the repercussions can ripple through various applications that rely on them.
- Example: If an e-commerce site’s payment processing API fails, it can prevent transactions across the entire platform, impacting sales and customer trust.
- Dependency Awareness: Development teams must understand the dependencies between their APIs and other services to mitigate potential risks.
- Proactive Measures: Implementing strategies to handle failures, such as retries or fallbacks, can help minimize the impact of these failures.
The Importance of API Resiliency Testing
API resiliency testing is critical for identifying weaknesses before they lead to production failures. This proactive testing approach ensures APIs can handle adverse conditions without significant disruptions.
- Early Detection: By simulating failures, teams can detect issues early in the development cycle, allowing for timely fixes.
- User Experience: Resilient APIs enhance user satisfaction by providing consistent service, even during unexpected outages.
- Cost Reduction: Addressing issues before they escalate can save organizations from costly downtime and recovery efforts.
Common Practices in Resiliency Testing
Several practices can enhance API resiliency testing, ensuring that APIs are robust and reliable.
- Negative Functional Testing: This involves testing how an API responds to invalid inputs or unexpected conditions. For example, sending null values for required fields can help identify potential failure points.
- Chaos Engineering: This practice involves intentionally introducing failures into the system to observe how it behaves. By simulating outages or performance degradations, teams can assess the API’s resilience.
- Load Testing: Understanding how an API performs under high traffic conditions is crucial. Load testing helps identify bottlenecks and ensures that the API can scale effectively.
- Monitoring and Observability: Implementing robust monitoring solutions allows teams to track API performance in real-time. Observability tools can provide insights into how APIs behave under various conditions.
Negative Functional Testing Explained
Negative functional testing focuses on how an API handles invalid or unexpected inputs. This form of testing is essential for building resilient APIs that can withstand misuse or errors from clients.
- Boundary Case Analysis: Testing the limits of input values helps ensure that APIs can handle edge cases gracefully.
- Simulating Errors: By intentionally causing errors, such as timeouts or unavailable services, teams can evaluate how well the API recovers from failures.
- Validation Checks: Implementing and testing validation checks ensures that APIs reject invalid requests before they can cause issues downstream.
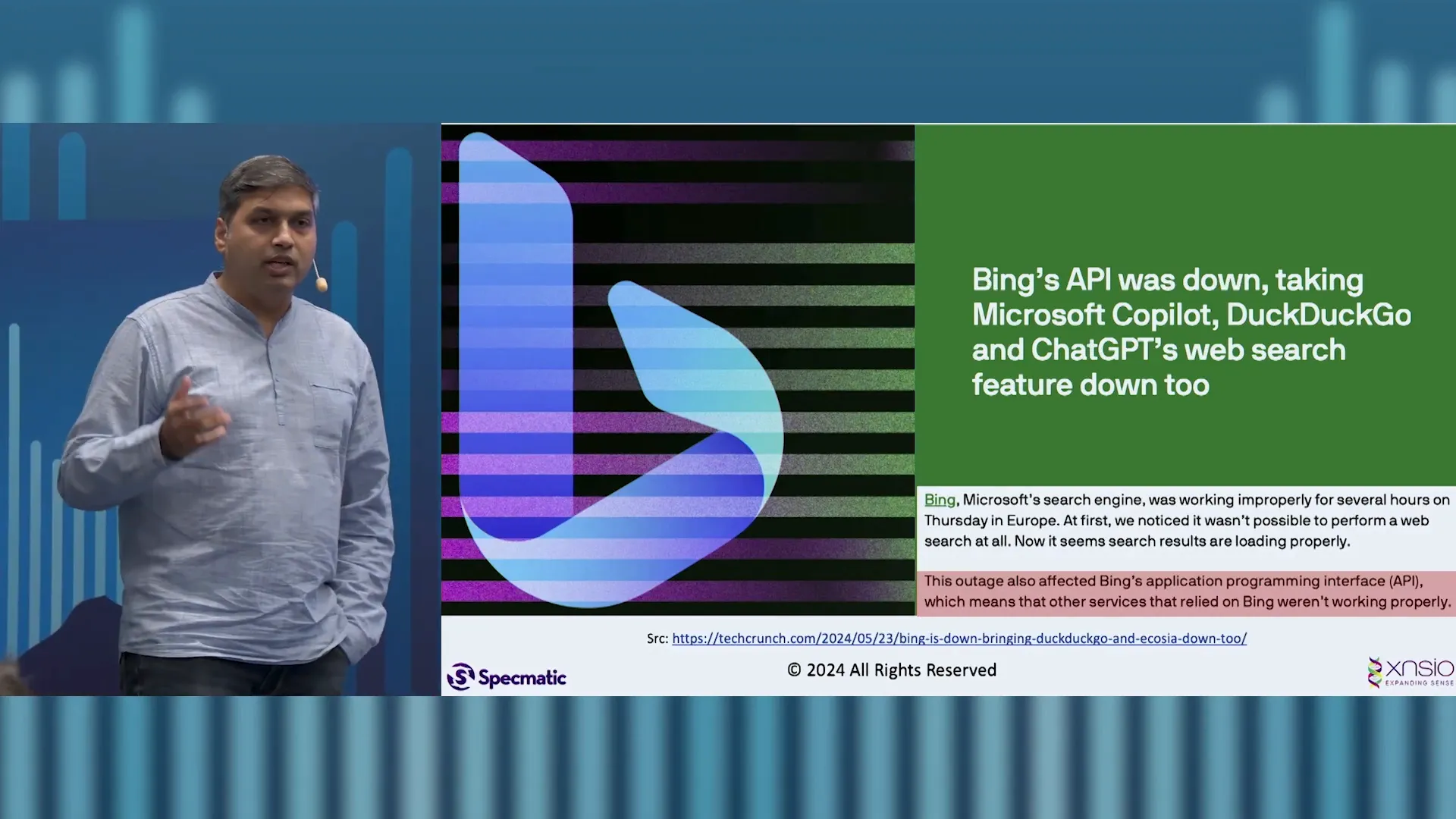
Chaos Engineering and Fault Injection
Chaos Engineering is a discipline that focuses on improving system resilience by deliberately introducing faults into a system. This proactive approach allows teams to observe how applications respond under stress and identify weaknesses before they manifest in production.
Fault injection, a key aspect of Chaos Engineering, involves simulating failures in a controlled environment. By doing so, developers can assess the robustness of their APIs and ensure they can handle unexpected conditions gracefully.
- Controlled Experiments: Teams can run experiments to test how APIs behave under various failure scenarios, such as network outages or service unavailability.
- Real-World Simulation: By mimicking real-world issues, teams can better prepare for genuine outages and unexpected behavior.
- Learning and Improvement: Insights gained from these experiments can drive improvements in the API design and implementation, leading to more resilient systems.

Performance Testing Considerations
Performance testing is crucial to ensure that APIs can handle the expected load efficiently. As user demands increase, APIs must be capable of scaling without compromising performance.
- Load Testing: This involves simulating a high number of concurrent users to see how the API performs under stress. Identifying bottlenecks can help optimize resource allocation.
- Stress Testing: Pushing the API beyond its limits helps determine the breaking point and assess how it recovers from failure.
- Endurance Testing: This tests the API’s performance over an extended period, ensuring it can maintain efficiency over time without degradation.

Building Observability into APIs
Observability is key to understanding the health and performance of APIs. By implementing robust monitoring solutions, teams can gain insights into API behavior, allowing for proactive issue resolution.
- Logging: Detailed logs provide visibility into API requests and responses, helping to trace errors and performance issues.
- Metrics Collection: Gathering metrics on response times, error rates, and request volumes enables teams to track API performance over time.
- Tracing: Distributed tracing allows teams to follow requests as they flow through various services, identifying bottlenecks and failures.

Live Demo: Testing an Order Service
In this section, we will demonstrate how to test an order service using an API specification. This hands-on approach illustrates how to implement API resiliency testing effectively usingh Specmatic.
The order service interacts with a product service to fetch product details. We will set up scenarios to test various aspects of the service’s resiliency.
- Initial Setup: Start by running tests against the order service to ensure it functions as expected under normal conditions.
- Simulating Faults: Introduce faults, such as timeouts or service unavailability, to observe how the order service handles these scenarios.
- Testing Recovery: Assess the order service’s ability to recover from faults and return to normal functionality.
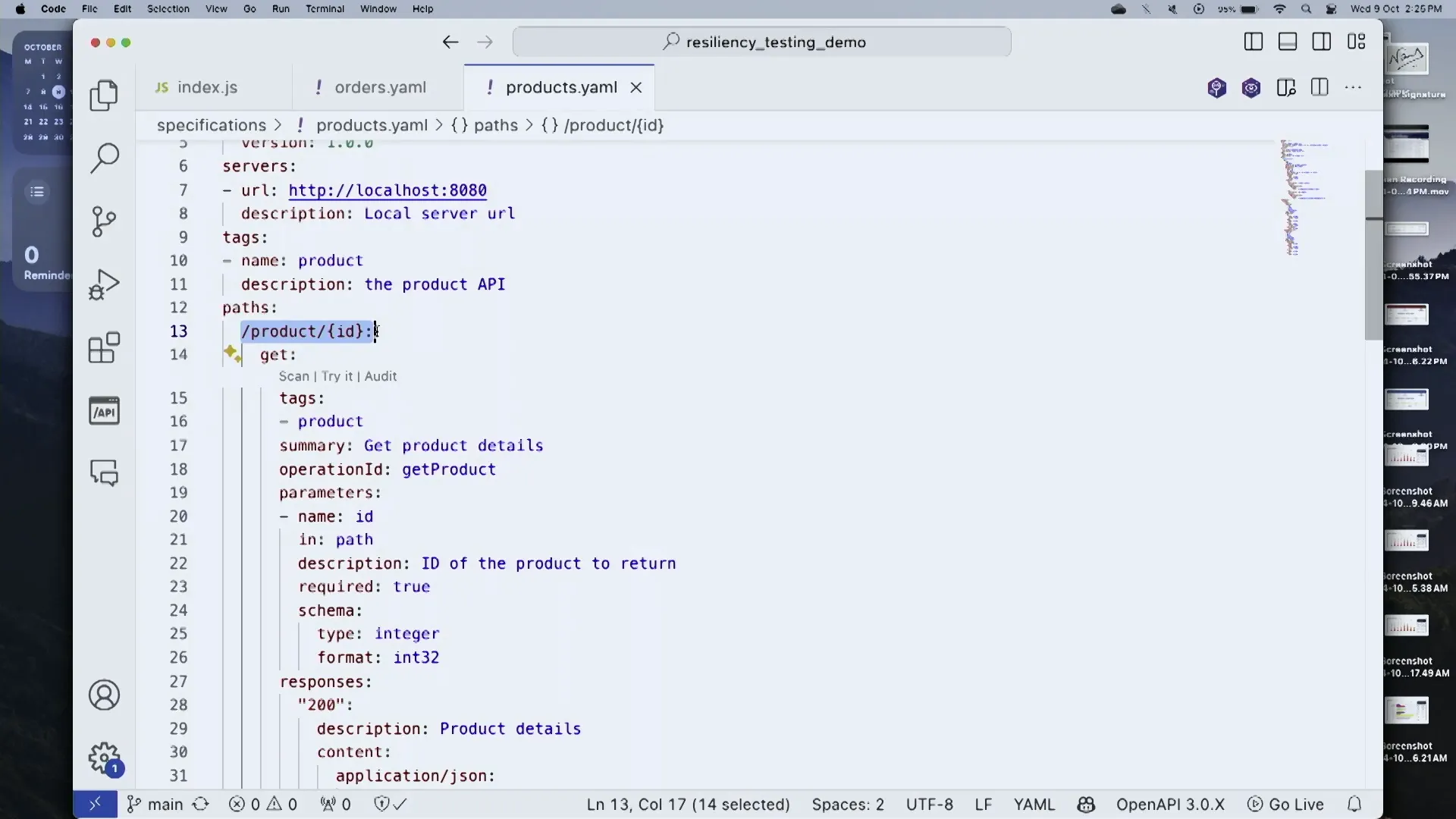
Simulating Timeout Responses
Timeout responses are a common issue that can disrupt API functionality. By simulating these scenarios, teams can ensure their APIs handle timeouts gracefully.
In our demonstration, we will introduce a delay in the product service to simulate a timeout. This allows us to observe how the order service responds.
- Introducing Delays: Set a delay in the product service response to simulate a timeout scenario.
- Response Handling: Modify the order service to handle timeouts by returning a 202 response, indicating that the request has been accepted for processing.
- Testing Resilience: Run tests to verify that the order service behaves as expected, even under timeout conditions.
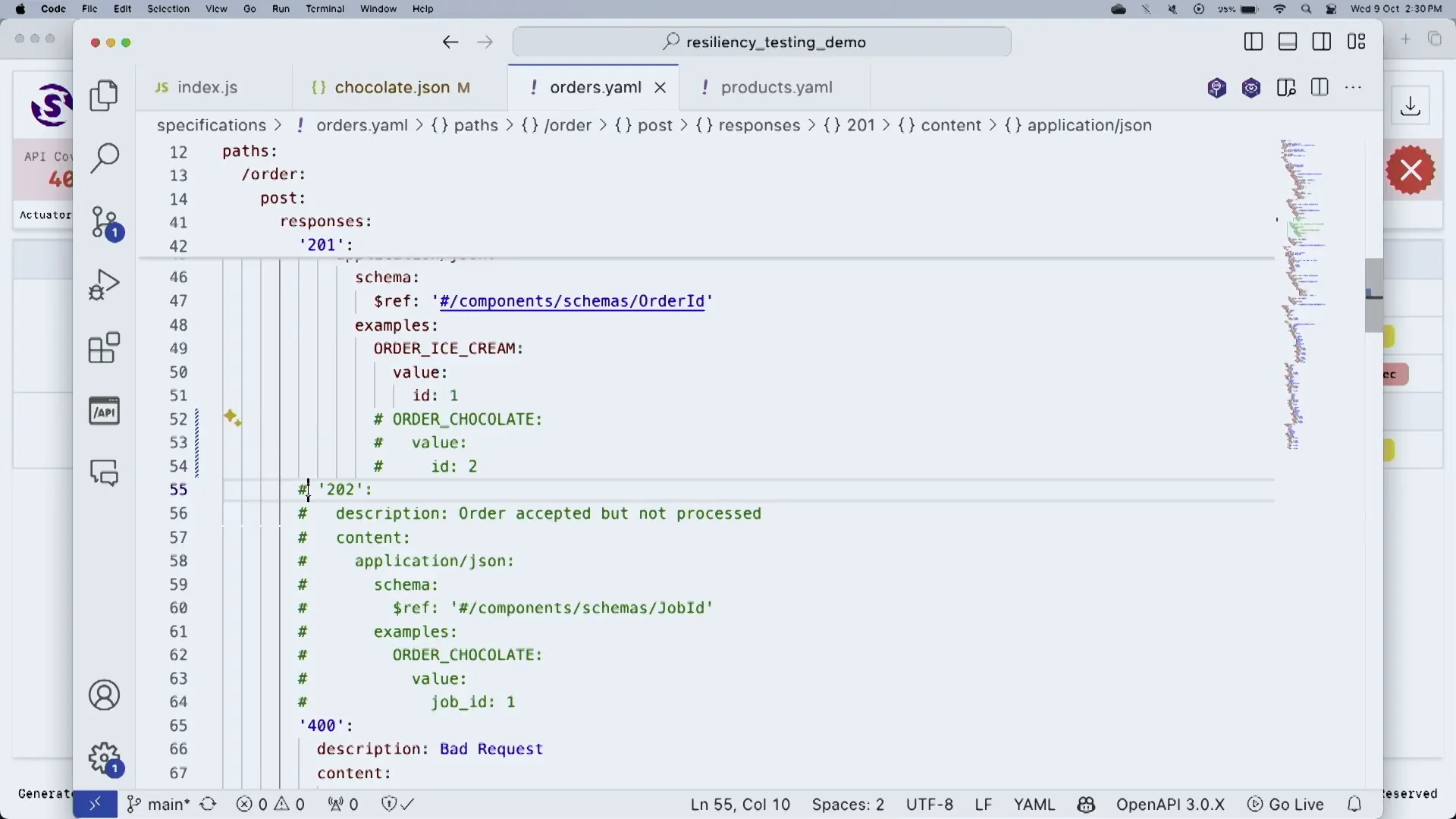
Updating API Specifications for Resiliency
One of the foundational steps in enhancing API resiliency is updating API specifications to accurately reflect expected behaviors under various conditions. This process involves defining how APIs should respond to different scenarios, including failure cases.
When an API specification is updated, it should include handling for both successful responses and error states. For instance, if the downstream service times out, the API should return a 202 response instead of a 500 error. This proactive approach helps maintain a seamless user experience even during failures.
Steps to Update API Specifications
- Identify Failure Scenarios: Determine potential failure points that the API may encounter, such as timeouts, invalid inputs, or downstream service failures.
- Define Response Codes: Specify appropriate HTTP status codes for each scenario. For example, a timeout might warrant a 202 status code indicating that the request has been accepted for processing.
- Document Expected Behavior: Clearly document how the API should behave in each failure scenario, ensuring that consumers understand the implications of different responses.
- Review and Iterate: Regularly review the specifications to incorporate new insights gained from testing and real-world usage. This iterative process ensures that the API evolves to meet changing requirements.
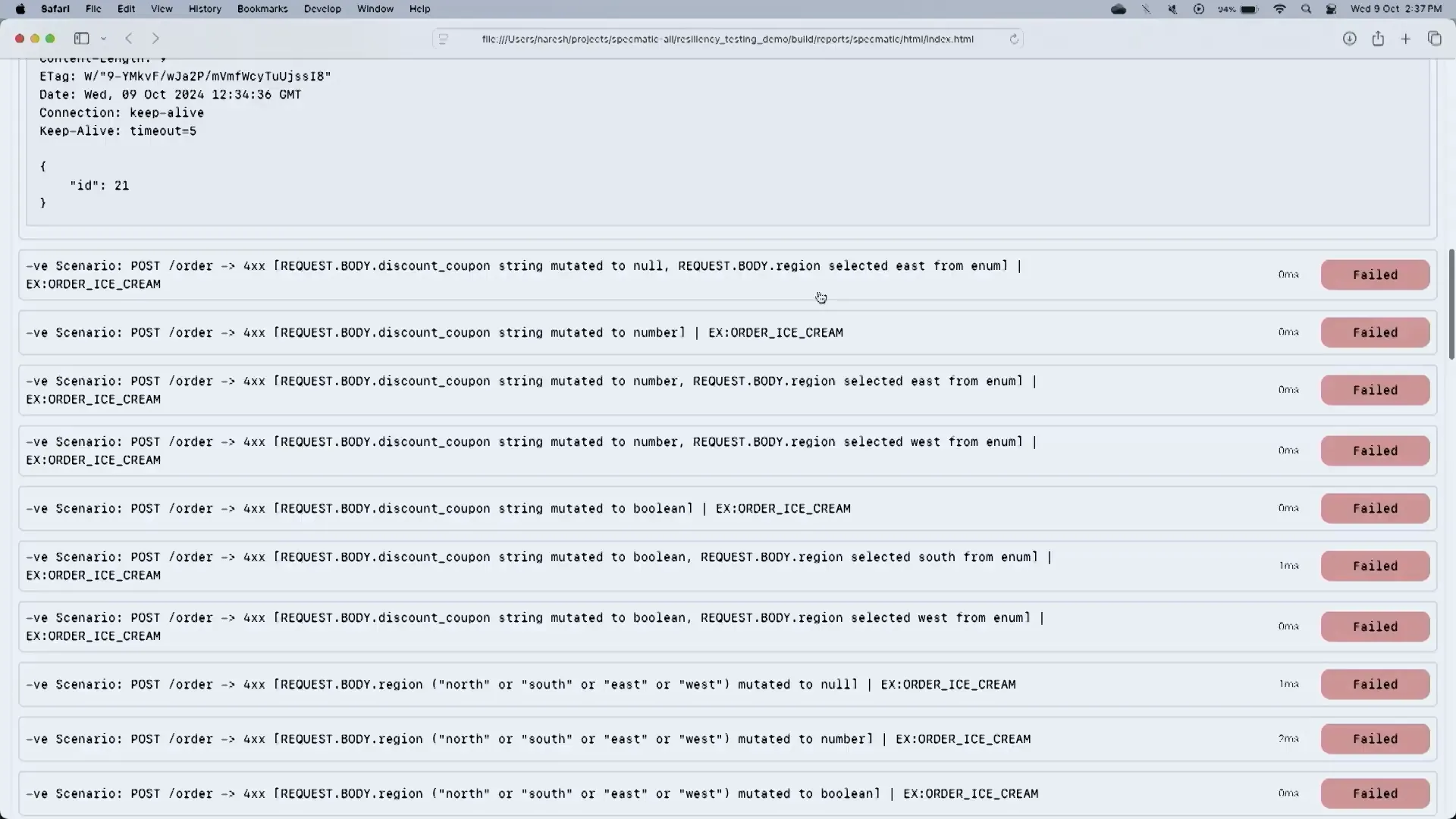
Testing for 400 Series Errors
Testing for 400 series errors is crucial for ensuring that APIs can gracefully handle client-side errors. These errors often occur due to invalid inputs or requests that do not meet the API’s requirements.
To effectively test for 400 series errors, developers should implement negative testing scenarios that simulate various types of invalid requests. This testing helps identify gaps in input validation and error handling.
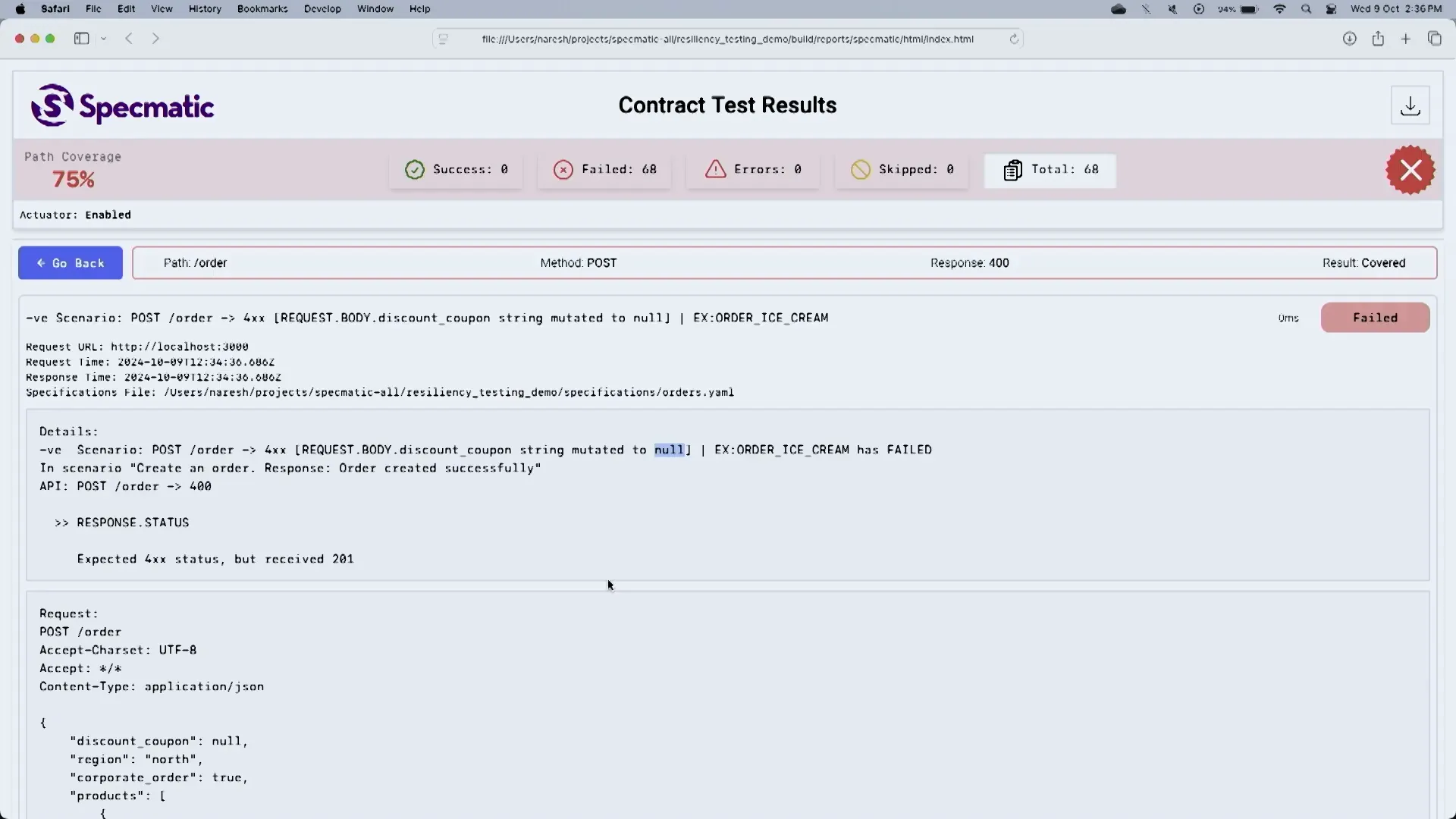
Common 400 Series Error Scenarios
- Invalid Input: Sending data types that do not match the expected format, such as null values for required fields.
- Out of Range Values: Providing numerical inputs that exceed predefined limits or fall below acceptable thresholds.
- Malformed Requests: Sending requests that do not adhere to the specified API structure, such as missing required parameters.
- Unauthorized Access: Attempting to access resources without proper authentication or permissions.
Using Middleware for Input Validation
Implementing middleware for input validation is an effective strategy for enhancing API resiliency. Middleware acts as a gatekeeper, ensuring that only valid requests reach the core API logic.
By applying validation rules consistently across all API endpoints, developers can reduce the likelihood of encountering 400 series errors during runtime. This approach also simplifies error handling by centralizing validation logic.
Benefits of Middleware for Input Validation
- Consistent Validation: Middleware ensures that validation rules are applied uniformly across all API requests, reducing duplicate code.
- Early Error Detection: By validating incoming requests before they reach the main application logic, middleware can catch errors early, improving overall system stability.
- Enhanced User Experience: Providing clear error messages in response to invalid inputs helps users understand what went wrong and how to correct it.
- Improved Maintainability: Centralized validation logic makes it easier to update and manage validation rules as the API evolves.
Summary of Key Insights
API Resiliency Testing is a critical practice for modern applications, ensuring that APIs can effectively handle unexpected scenarios without significant disruptions. Key insights from this discussion include:
- Proactive API Design: Updating API specifications to define expected behaviors in failure scenarios is essential for building resilient APIs.
- Thorough Testing: Testing for 400 series errors through negative testing scenarios helps identify weaknesses in input validation.
- Middleware Implementation: Utilizing middleware for input validation centralizes error handling and improves overall API robustness.
- Iterative Improvement: Regularly reviewing and updating API specifications and testing strategies ensures that APIs evolve in response to real-world usage.
FAQs on API Resiliency Testing
What is API Resiliency Testing?
API Resiliency Testing involves evaluating how well an API can withstand failures and unexpected conditions, ensuring that it continues to function correctly and provide meaningful responses to users.
Why is input validation important in API Resiliency Testing?
Input validation is crucial because it prevents invalid data from reaching the core application logic, reducing the likelihood of errors and enhancing the overall stability of the API.
How can middleware improve API resiliency?
Middleware like Specmatic can improve API resiliency by centralizing input validation, ensuring consistent application of validation rules, and providing early error detection to enhance user experience.
What are common practices for testing 400 series errors?
Common practices include simulating invalid inputs, testing for out-of-range values, sending malformed requests, and checking for unauthorized access attempts.
How often should API specifications be reviewed and updated?
API specifications should be regularly reviewed and updated based on insights gained from testing, user feedback, and changes in requirements to ensure they remain relevant and effective.